




Discounts are the easiest way to hold onto subscribers — and the most expensive. ISPs that build revenue growth around behavior-based retention protect margins while increasing what each subscriber is worth over time. The telecom operators with the strongest ARPU growth are not the ones offering the lowest prices — they are the ones building loyalty into the subscriber journey from day one.
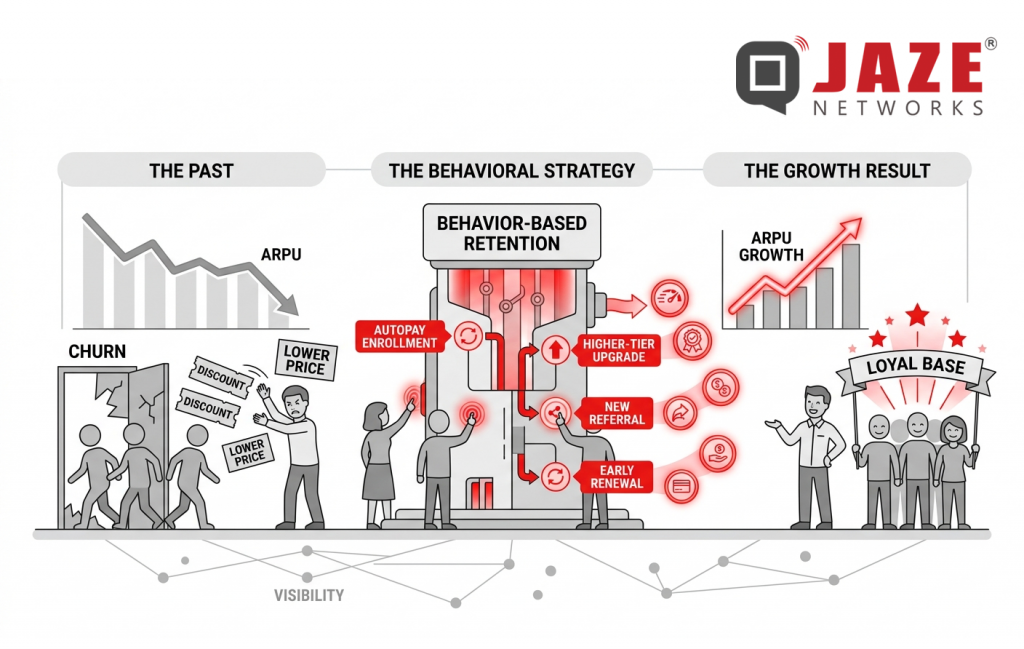
Growing revenue per subscriber used to mean upselling to bigger plans or bundling more services. That approach is losing steam. Subscribers are more price-sensitive than ever, and most ISPs in a given market offer similar packages at similar price points. Competing on price is a race with no clear winner.
The deeper problem: most ISPs chase ARPU growth through acquisition. When churn stays high, every new subscriber gained simply replaces one who left — and acquisition costs keep rising without any real gain in recurring revenue.
The smarter path is growing revenue within your existing base. Your highest-value subscribers are already on your network. The goal is to give them concrete reasons to stay, spend more, and move up the plan ladder — without dropping prices.
A behavior-based retention model shifts focus from reactive discounts to proactive engagement. Instead of offering a price cut when a subscriber threatens to leave, you reward actions that reinforce long-term commitment before that moment ever arrives.
These are not random perks — they map to specific moments in the subscriber journey where loyalty is built or lost.
Here are the behaviors worth incentivizing:
Each of these moments builds subscriber stickiness. Users who feel recognized for loyalty are more likely to stay, explore additional services, and refer new subscribers to your network. ARPU increases because subscribers voluntarily move up — not because they were pressured into it by a renewal call.
This approach does not require ongoing discounts. Perceived value — priority access, recognition, and perks tied to specific actions — drives the same behavior without eroding your margins.
Executing a retention-first ARPU strategy depends on having the right data at the right time. ISP operators need real-time visibility into:
An offer sent too late — or to the wrong subscriber — has no impact. Without lifecycle visibility, that is exactly what happens.
Without this wider view, retention stays reactive. You find out a subscriber is leaving when the cancellation request arrives — not three weeks earlier when there was still time to act.
Manual processes cannot keep pace. When your billing system does not connect to your support data, and your support data does not connect to provisioning records, the gaps between those systems are where subscribers fall through. The ISPs growing ARPU year over year run their entire operation from a single connected platform — not a collection of disconnected tools patched together with spreadsheets.
Jaze ISP Manager gives ISP operators a complete view of the subscriber lifecycle — from onboarding to renewal — in a single dashboard. Built-in billing automation tracks plan status and renewal dates, while the subscriber self-service portal and mobile app create ongoing engagement touchpoints between billing cycles. Operators can identify upgrade candidates, flag at-risk accounts, and act on retention signals before subscribers start looking elsewhere.
Click here to know more.
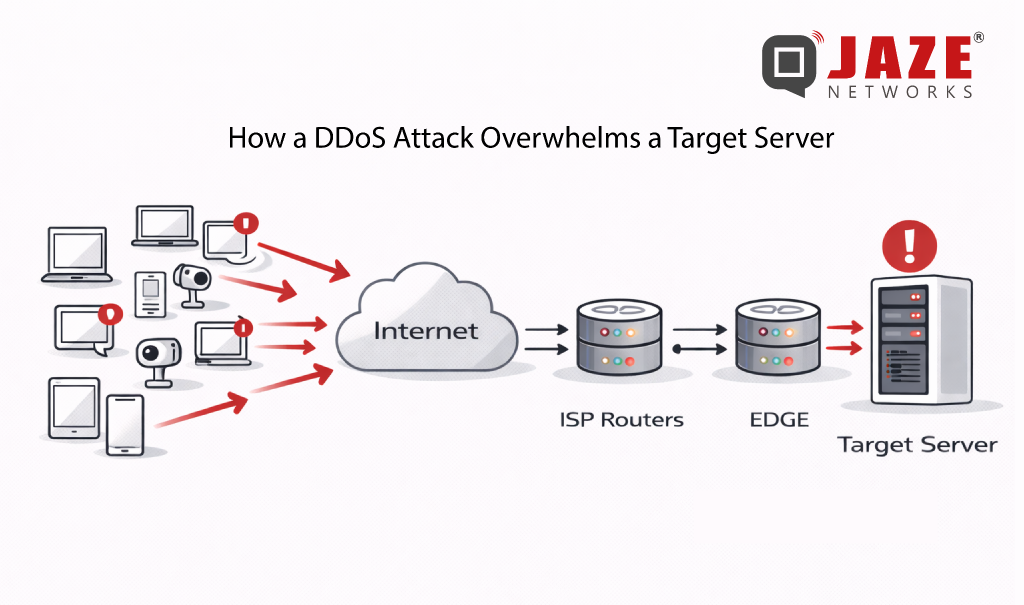
DDoS attacks are no longer rare, large-scale events. Volumetric floods exceeding hundreds of gigabits per second are now routine — and for ISPs, the damage isn’t just to the targeted subscriber. Congestion cascades across shared infrastructure, degrading service for everyone on the network. The question isn’t whether your network will face a DDoS attack. It’s how fast you can stop one.
BGP Flowspec is the answer most network operators are turning to — and for good reason. It combines the speed of BGP route propagation with the precision of granular traffic filtering, giving ISPs surgical control over attack traffic without disrupting legitimate users.
From Blunt to Precise: The Evolution Beyond RTBH
Before Flowspec, Remote Triggered Black Hole (RTBH) filtering was the go-to mitigation tool. RTBH works by routing all traffic destined for an attacked IP address to a null route — effectively dropping everything. It works fast, but it’s indiscriminate: legitimate traffic to that host gets silently discarded alongside the attack traffic.
BGP Flowspec (defined in RFC 5575 and extended in RFC 8955) was developed to solve this problem. Rather than blackholing an entire destination, Flowspec lets operators define detailed traffic rules based on multiple attributes simultaneously — and distribute those rules across the network in seconds via BGP.
What Makes BGP Flowspec Powerful
Flowspec rules can match traffic using a combination of:
• Source and destination IP addresses or prefixes
• Source and destination port numbers
• IP protocol (TCP, UDP, ICMP, etc.)
• Packet length and DSCP markings
• TCP flags (SYN, ACK, RST, etc.)
Once a rule is created, Flowspec propagates it to all BGP-peered routers — including upstream providers and transit peers — in real time. Instead of one appliance scrubbing traffic at a single point, the entire network perimeter reacts simultaneously.
Supported actions include rate-limiting specific traffic types, redirecting flows to scrubbing centers, tagging packets with DSCP values for QoS treatment, or dropping traffic outright. This flexibility makes Flowspec equally useful for volumetric UDP floods, TCP SYN attacks, and reflection/amplification attacks.
How Mitigation Works in Practice
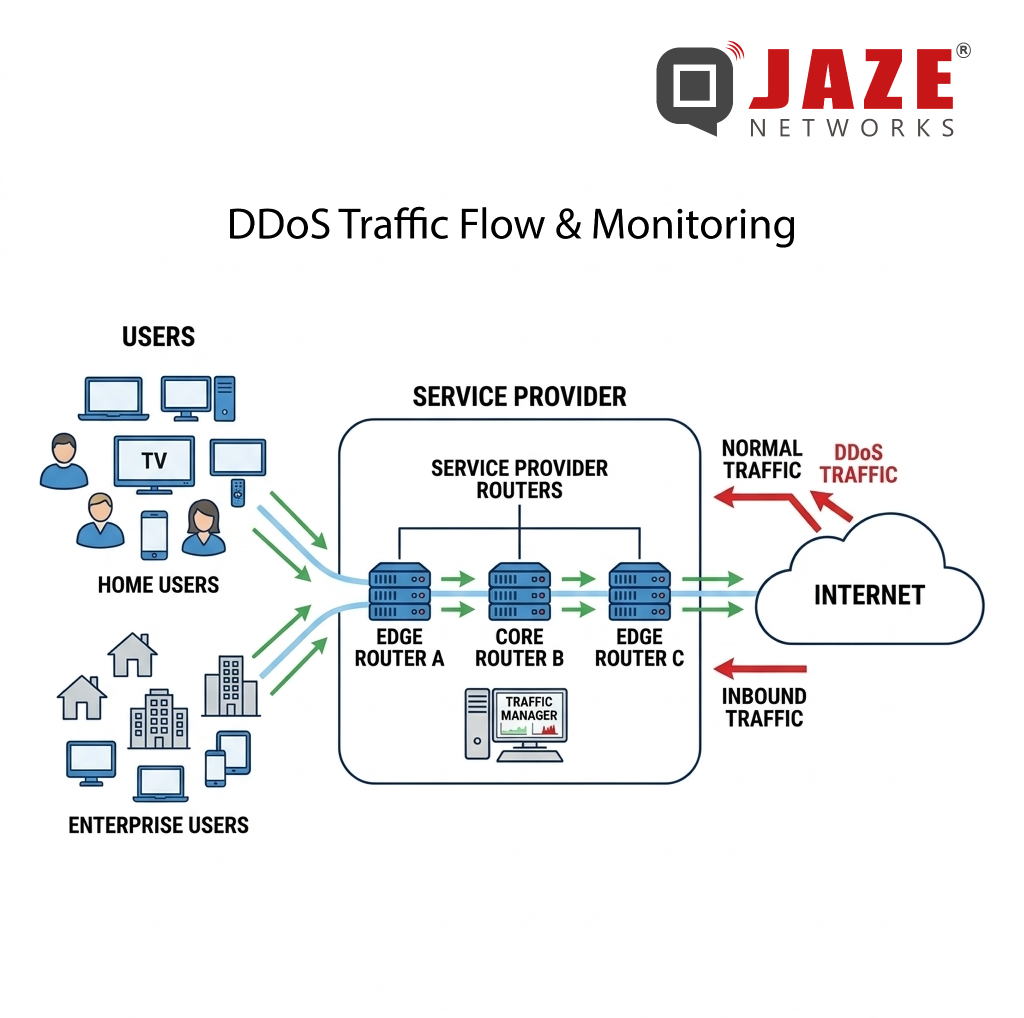
In a typical deployment, traffic telemetry — from NetFlow, IPFIX, or sFlow — is continuously analyzed by a detection system. When an attack signature is identified, the system automatically generates a Flowspec rule and announces it via BGP to all participating routers.
The entire cycle — detection, rule creation, propagation, enforcement — can complete in under 30 seconds. At attack scale, that speed is the difference between a 5-minute blip and a 45-minute outage.
Because Flowspec rules target specific traffic characteristics rather than IP addresses, legitimate users on the same subnet or hosting the same services are unaffected. The attack is blocked; normal traffic continues.
Vendor Support and Deployment Considerations
BGP Flowspec is supported across all major network equipment vendors — Cisco, Juniper, Huawei, Nokia, and Arista all implement it natively in their router operating systems. However, implementation depth varies: some platforms support only basic match criteria, while others support the full RFC 8955 attribute set.
For ISPs deploying Flowspec, key planning decisions include:
• Which routers will act as Flowspec clients (receiving and enforcing rules)
• Whether upstream transit providers also support Flowspec peering
• How detection thresholds are tuned to minimize false positives
• Whether mitigation is manual, semi-automated, or fully automated
Automated Flowspec deployment — where detection and rule announcement happen without human intervention — is now the standard approach for ISPs handling large subscriber bases. Manual processes are too slow when an attacker can saturate uplinks in seconds.
Flowspec and RTBH: Complementary, Not Competing
Flowspec doesn’t make RTBH obsolete. For attacks where the traffic source is clearly identified and the targeted IP has no legitimate inbound traffic (a server in maintenance, for example), RTBH remains faster to deploy and simpler to manage.
A mature ISP DDoS strategy uses both: RTBH for immediate, coarse-grained isolation and Flowspec for precise, sustained mitigation that preserves service availability for other subscribers on the same prefixes.
Jaze ISP Manager provides scalable IPFIX logging which can be integrated with DDoS protection systems for real-time DDoS detection and mitigation. In integration with BGP routers supporting RTBH and BGP Flowspec , ISPs can detect, respond to, and neutralise DDoS attacks before service is disrupted — keeping subscribers connected and SLAs intact.
Click here to see how Jaze ISP Manager helps in delivering scalable IPFIX logging services.
The rise of artificial intelligence has created a new breed of data center—one that demands unprecedented levels of power, cooling, and most critically, network performance. Unlike traditional data centers that handle everyday computing tasks, AI data centers are purpose-built facilities for training and running large-scale machine learning models.
Understanding what makes these facilities unique helps explain why network infrastructure has become the make-or-break factor in AI success.
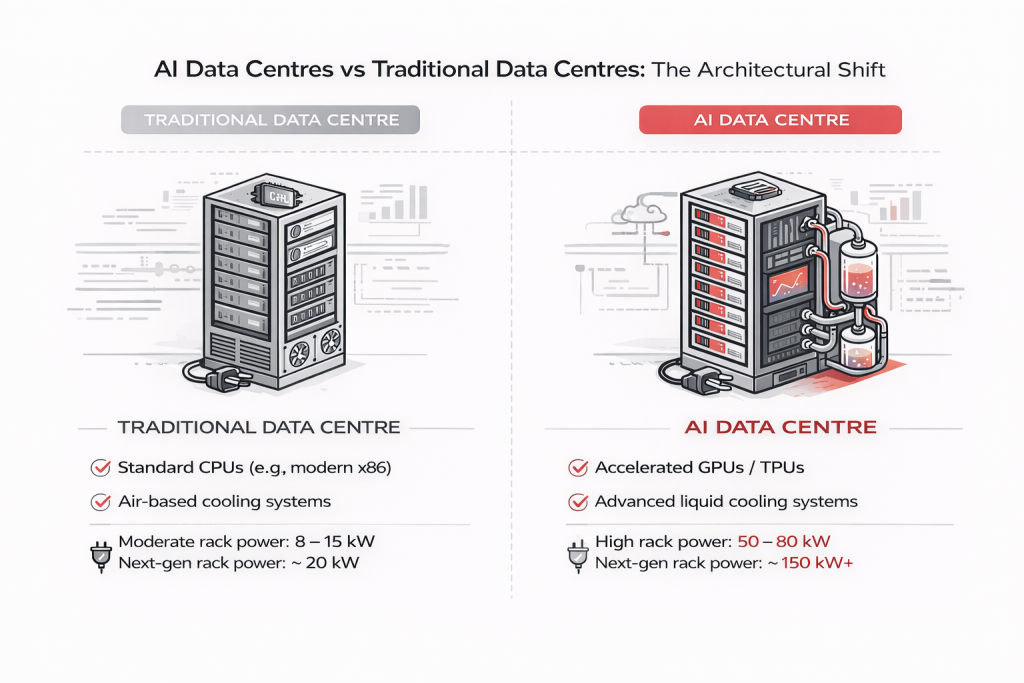
Traditional data centers are generalists. They run business applications, host websites, store databases, and handle email servers. Each task operates independently with moderate resource demands.
AI data centers are specialists built for one primary function: training and running neural networks at massive scale. This singular focus reshapes everything from processor choice to building design.
The fundamental shift starts with processors.
Traditional data centers rely on CPUs designed to handle diverse, sequential tasks efficiently—perfect for running varied business applications.
AI data centers are built around GPUs (Graphics Processing Units) and specialized AI accelerators like TPUs. These chips contain thousands of simple cores working in parallel, ideal for the repetitive mathematical operations required in machine learning.
Training an AI model requires massive parallel processing. Where a CPU handles tasks sequentially, a GPU operates like thousands of workers performing identical operations simultaneously.
Here’s where AI data centers diverge completely from traditional thinking.
Servers communicate occasionally. Standard Ethernet handles sporadic, low-volume traffic between independent systems.
Thousands of GPUs must operate as a single unified system. When training large models, processors constantly synchronize their work, exchanging terabytes of data with near-zero latency tolerance.
Even milliseconds of delay cascade into hours of wasted training time. This demands:
Without proper network infrastructure, multi-million dollar GPU clusters operate at a fraction of their potential.
AI computation generates extreme heat. Standard server racks draw 5-10 kilowatts. AI-optimized racks consume 50-100 kilowatts—equivalent to powering 20 homes from a single cabinet.
Air cooling cannot handle this density. Modern AI facilities use:
This physical complexity demands careful planning and monitoring to maintain optimal performance.
AI training consumes massive datasets—petabytes of images, text, and video. Unlike traditional databases, AI storage operates like a high-speed conveyor belt delivering continuous data streams to thousands of GPU workers.
Success requires:
The bottleneck isn’t finding data—it’s moving it fast enough to keep GPUs fully utilized.
AI data centers aren’t retrofitted warehouses. They’re industrial facilities designed from the ground up:
Managing AI data center networks presents unique challenges:
Scale: Thousands of 400G/800G fiber connections between GPU clusters, storage, and control systems.
Interdependence: Systems are tightly coupled. Network degradation directly impacts GPU utilization and training efficiency.
Performance Sensitivity: AI workloads expose network issues that traditional applications tolerate.
Rapid Evolution: Infrastructure changes constantly as new GPU generations and networking technologies emerge.
Organizations need robust network infrastructure capable of supporting these demanding workloads while maintaining visibility and control.
Current AI models are limited by available infrastructure. Future demands will intensify:
With higher network bandwidth requirements triggered by AI, bandwidth consumption for broadband is set to surge higher. With higher bandwidth requirements, ISPs and telcos need to handle increased loads on their BSS and Logging solutions. Jaze ISP Manager provides a scalable architecture to adopt to increased loads on their infrastructure without incurring significant hardware investment. Click here to discover how Jaze ISP Manager supports a scalable architecture for large scale ISP networks. Click here to learn more.