




On November 18, 2025, a major disruption rippled across the internet when Cloudflare—one of the world’s most widely used internet infrastructure providers—experienced a significant service outage. Because Cloudflare supports millions of websites with DNS, CDN caching, traffic filtering, API routing, and security layers, even a single malfunction can create global-level instability. And that’s exactly what millions of users witnessed that day: slow loading pages, apps refusing to open, authentication failures, and entire platforms temporarily unreachable.
While outages are not new in the digital world, this one stood out because of how deeply Cloudflare sits in the modern connectivity pipeline. In many ways, the incident offered a real-world reminder of how much of the internet relies on a few key infrastructure players.
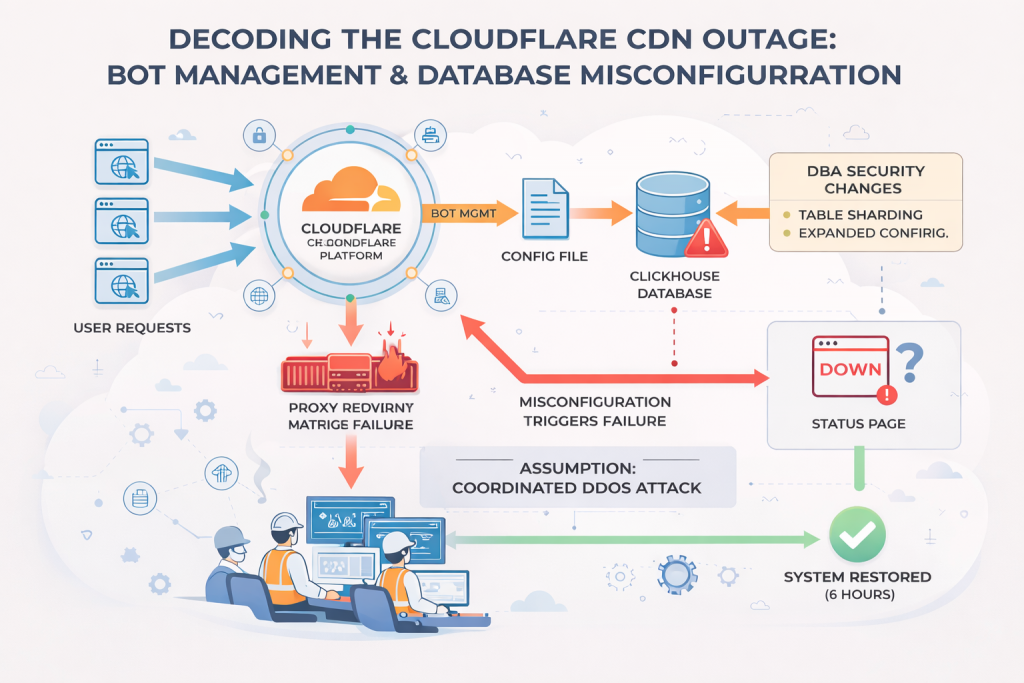
According to Cloudflare’s engineering investigation, the root cause was a faulty internal configuration deployed to part of their network. This configuration affected a critical service responsible for evaluating incoming requests and filtering harmful traffic. When the service encountered the corrupted configuration file, it failed in a “closed” state—meaning instead of allowing traffic through when uncertain, it blocked it.
This resulted in a surge of HTTP 5XX errors, especially 500 and 503 responses, which are typical indicators of server-side failures. Users around the world soon realized that websites using Cloudflare were timing out, stalling, or redirecting to error pages.
Unlike outages caused by connectivity failures or cyberattacks, this event was self-inflicted by a software deployment that didn’t behave as expected. Small configuration issues can have an outsized impact in distributed systems, and this incident highlighted how even a single misconfiguration in a shared global network can cascade quickly.
When Cloudflare pushed the problematic update, only part of the network received it at first. This meant some nodes were functioning normally while others were rejecting legitimate requests. As traffic routing systems attempted to balance loads across these nodes, users received unpredictable experiences—one moment a service worked, the next it failed.
This “flapping” behavior created instability until Cloudflare engineers isolated the issue, rolled back the configuration, and restored normal operations. Because Cloudflare’s infrastructure is interconnected, the rollback had to be done carefully to avoid further disruptions.
The outage lasted several hours for some regions, though others recovered sooner depending on local routing and DNS propagation.
The disruption was widely felt because Cloudflare isn’t simply a website host—it acts as a performance booster, security layer, and traffic gateway for businesses large and small. Popular platforms relying on Cloudflare for DNS or CDN saw sudden performance drops. E-commerce portals, SaaS dashboards, streaming services, and even mobile apps that depend on API calls struggled to function.
For many businesses, this meant:
Even organizations that had redundant hosting infrastructure were affected if they used Cloudflare for routing or DNS resolution.
Although Cloudflare increases performance and security for millions of websites, the outage showed how a single point of failure can disrupt a huge portion of online activity. Centralization offers efficiency but also creates vulnerability.
Many companies invest in multi-cloud or backup environments, but rely on a single provider for DNS or CDN. The outage highlighted why redundancy must cover every layer of the stack, including traffic routing and security services—not just compute resources.
Modern cloud platforms are highly automated, but that also means configuration errors can spread extremely fast. Even with safety checks, edge cases slip through. The best protection is layered testing, staged rollouts, and real-time anomaly detection.
Cloudflare acted quickly, pausing the rollout and identifying the failing component. Engineers issued a rollback, restarted affected services, and published a transparent incident update. Their communication emphasized that the issue was not caused by an attack, but by an internal logic failure during deployment.
The company also announced improvements to configuration validation, emphasizing stronger safeguards to prevent similar issues in the future.
The November 2025 outage is a valuable case study for businesses that rely heavily on cloud-based traffic tools:
Most importantly, organizations must acknowledge that outages are inevitable. The real question is how resilient the architecture remains when a critical provider becomes unavailable.
The Cloudflare outage of November 18, 2025 was a reminder of the complexity and fragility of the internet’s backbone. While Cloudflare resolved the issue efficiently and transparently, the event highlighted how interconnected digital services have become.
While ISPs cannot protect themselves from technical issues with the Internet, they can definitely adopt tools that strengthen operational visibility and fault management. Jaze ISP Manager provides powerful helpdesk and task management features to help teams detect and respond to internal outages faster.
The Internet today works much like a vast and rapidly expanding city. Every device — whether it’s your phone, laptop, or home router — needs a unique address to send and receive information. For decades, this addressing system depended on IPv4, a 32-bit structure that was perfectly adequate when the Internet was small.
However, as more people, devices, and services connected online, IPv4’s supply of addresses could no longer keep up with the growth. This shortage triggered the introduction of temporary workarounds and long-term solutions — the most significant being Carrier-Grade NAT (CGNAT) and IPv6.
To extend the lifespan of IPv4, many Internet Service Providers (ISPs) adopted Carrier-Grade NAT. Instead of assigning every user a unique public IP address, CGNAT enables multiple customers to share a single IP. Each household receives a private internal address, and a translation layer maps internal traffic to the shared public IP.
This approach successfully delayed IPv4 exhaustion, but it introduced several limitations. CGNAT disrupts the Internet’s original end-to-end communication model by placing translation devices in the middle of user connections. As a consequence, certain applications struggle to function correctly, especially those that rely on direct connectivity.
Port forwarding becomes extremely difficult, sometimes impossible. This affects use cases such as home servers, online gaming, peer-to-peer applications, remote access setups, and more. Additionally, when multiple users share the same public IP, identifying the source of spam, abuse, or cyberattacks becomes far more complex. These challenges make CGNAT a useful but imperfect solution.
IPv6 was created as a permanent and future-proof alternative to IPv4. With its 128-bit address space, IPv6 provides an enormous pool of unique public addresses — enough for every device on Earth and many more.
Unlike CGNAT-based IPv4 setups, IPv6 supports true end-to-end connectivity. Every device can be globally reachable without relying on NAT layers or port mapping workarounds. This leads to cleaner network designs, lower complexity, improved reliability, and better performance for applications that require direct communication.
Despite its advantages, IPv6 adoption has been slower than expected. Many networks still run primarily on IPv4 infrastructure, and not all devices or applications fully support IPv6. In some cases, IPv6 is deployed using the same philosophies as IPv4 NAT, reducing the benefits of the protocol due to outdated design assumptions.

The differences between CGNAT and IPv6 become clear when examining common real-world scenarios:
In essence, CGNAT introduces friction for modern, interactive Internet use cases, while IPv6 aligns naturally with today’s connectivity needs.
Migrating an entire global Internet ecosystem is complex. Several factors slow down IPv6 deployment:
To move forward, ISPs must embrace native IPv6 routing instead of leaning on NAT-based stopgaps. Device manufacturers and service providers should treat IPv6 compatibility as mandatory, not optional. Developers and technical professionals need to adopt IPv6-first design principles to ensure smooth interoperability.
CGNAT has played an important role in extending the life of IPv4, but its limitations are increasingly apparent. It complicates connectivity, affects performance, reduces transparency, and restricts how users interact with the Internet.
IPv6, by contrast, provides scalability, efficiency, and true end-to-end communication — all essential for the modern digital ecosystem. While the transition is ongoing, IPv6 represents the Internet’s long-term foundation.
For users who rely on hosting, gaming, remote access, or advanced networking features, choosing an ISP that offers robust, native IPv6 routing can significantly improve their experience. For technology creators and providers, adopting IPv6-first development ensures long-term compatibility and reliability.
Ultimately, the future of the Internet is built on abundant addressing, simplified routing, and open connectivity — the principles that IPv6 was designed to deliver.
Jaze ISP Manager offers comprehensive solutions to help ISPs transition seamlessly to IPv6 with integration with all major BNG providers ensuring robust network performance and future-proof connectivity.